什么是Robots.txt
Robots.txt 是一个用于管理搜索引擎爬虫的文本文件。
使用Robots来指示搜索引擎爬虫哪些页面或部分内容可以被访问和索引,哪些不可以爬取。
Robots规则文件通常位于网站的根目录下,名称为 robots.txt。

为什么Robots.txt对谷歌SEO很重要?

控制搜索引擎爬虫访问
网站管理员控制哪些页面或部分内容可以被搜索引擎爬虫访问和索引。这有助于避免不必要的页面被索引,例如:
- 重复内容
- 临时页面或测试页面
- 后台管理页面
- 无关紧要或低质量的页面
通过限制这些内容,可以提高重要页面在搜索结果中的表现。
提高抓取效率
搜索引擎爬虫有一个抓取预算,即它们在每个网站上花费的时间和资源是有限的。通过使用 robots.txt 文件阻止爬虫访问无关或低价值的页面,可以将爬虫的抓取预算集中在更重要的页面上,从而提高这些页面的索引速度和频率。
屏蔽非公开页面
某些页面或文件可能包含敏感信息,不希望被公开搜索或索引。通过 robots.txt,可以阻止搜索引擎爬虫访问这些内容,从而防止它们出现在搜索结果中。
避免搜索引擎惩罚
一些搜索引擎(包括谷歌)可能会对重复内容、低质量页面或违反搜索引擎指南的内容进行惩罚。通过 robots.txt 文件,可以有效地管理和控制这些内容,避免不必要的搜索引擎惩罚,从而维护或提高网站的搜索排名。
正确使用Robots.txt的流程

1. Robots规则
格式规范:
- 文件命名:文件名必须为robots.txt,且全部字母小写。
- 存放位置:该文件应存放在网站的根目录下,即域名直接指向的目录。
- 格式:robots.txt文件应为纯文本文件,不包含任何HTML或脚本代码。
- 注释:可以使用#符号添加注释,注释内容不会被搜索引擎解析。
- 空行:为了提高文件可读性,可以在指令之间留有空行。
指令与规则:
robots.txt文件由一系列的指令组成,每个指令占一行。
常见的指令包括User-agent、Disallow、Allow和Sitemap。
User-agent
- 作用:指定以下规则适用的搜索引擎爬虫名称
- 语法:User-agent: [爬虫名称]。其中,*代表适用于所有爬虫
| 写法 | 说明 |
| User-agent: * | 适用于所有网络爬虫, 表示后续规则对所有爬虫都生效 |
| User-agent: Googlebot | 只适用于 Google 的爬虫 Googlebot |
| User-agent: Bingbot | 只适用于 Bing 的爬虫 Bingbot |
Disallow
- 作用:指定禁止爬虫访问的URL路径
- 语法:Disallow: [路径]。路径可以使用通配符*和$,其中*代表任意字符序列,$代表路径的结尾
| 写法 | 说明 |
| Disallow: / | 禁止访问整个网站, 爬虫不会抓取该网站的任何页面。 |
| Disallow: | 留空 Disallow 表示允许访问所有内容。 |
| Disallow: /*?* | 禁止访问包含查询参数的所有 URL(? 号后面的内容)。 |
| Disallow: /wp-admin/ | 禁止爬虫访问 WordPress 后台管理目录,避免抓取管理页面。 |
| Disallow: /wp-includes/ | 禁止爬虫访问 WordPress 核心文件目录,防止抓取核心功能文件。 |
| Disallow: /?s= | 禁止爬虫抓取搜索查询结果页面,以防止抓取大量无用的搜索结果页面。 |
注:特别强调 Disallow: / 不要轻易去配置,防止忘记取消,会导致全站不被收录。
Allow
- 作用:与Disallow相反,指定允许爬虫访问的URL路径。通常与Disallow一起使用,以覆盖更广泛的Disallow规则
- 语法:Allow: [路径],路径规则与Disallow相同。
- 示例:禁止爬虫访问整个 /wp-admin/ 目录,但需要允许访问 admin-ajax.php 文件。
| 示例写法 | 说明 |
| User-agent: * | 表示后续规则对所有爬虫都生效 |
| "Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php" |
"禁止爬虫访问整个 /wp-admin/ 目录 但允许访问其中的 admin-ajax.php 文件" |
Sitemap
- 作用:指定网站地图(Sitemap)的URL地址,帮助搜索引擎更好地抓取网站内容
- 语法:Sitemap: [URL]
| 写法 | 说明 |
| https://xxxx/sitemap.xml | 该网站的站点地图(Sitemap)文件位于该URL下 |
注意事项
区分大小写:搜索引擎爬虫对大小写敏感,因此在编写robots.txt文件时需要注意区分大小写。
有效性验证:编写完毕可以通过搜索引擎工具或在线验证工具来验证robots.txt文件的有效性。
避免误封禁:在编写规则时要仔细检查,确保不会误封禁重要的网页或资源。
定期更新:根据网站的变化情况,定期更新robots.txt文件是必要的。
2. 手动创建 Robots文件
使用文本编辑器创建一个新的文件,并命名为 Robots.txt。
在 robots.txt 文件中添加你希望搜索引擎遵循的规则,编写示例:

该文件表示:
- 所有爬虫都不允许访问 /admin/, /login/ 和 /private/ 目录,但允许访问 /public/ 目录。
- 仅谷歌爬虫不允许访问 /test/ 目录。
- 最后添加上网站的Sitemap
3. Robots文件上传到网站
将 robots.txt 文件上传到你的网站的根目录,下图以siteground虚拟主机为例:

4. 自动化创建 Robots文件
第三方建站系统:WordPress 可以搭配插件进行自动化设定
推荐插件:AIOSEO、Rank Math SEO、Yoast SEO、SEOPress
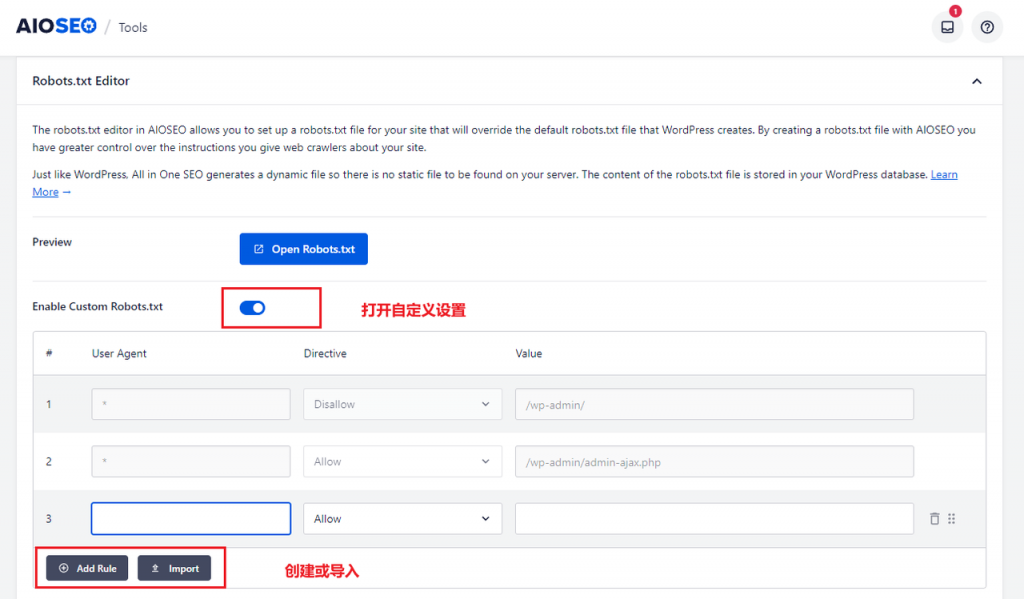
我这里使用AIOSEO插件生成Robots,具体示例如下:
在AIOSEO插件的Tools菜单栏目下,进行Robots.txt Editor ,先打开 Enable Custom Robots.txt 开关,然后 Add Rule或者 Import创建或导入Robots规则,最后保存即可看到实际效果。

创建后的数据呈现:
创建完成之后,在Custom Robots.txt Preview 这里就能看到实际效果,也可以访问:https://xxxx/robots.txt 进行查看。
注意事项:
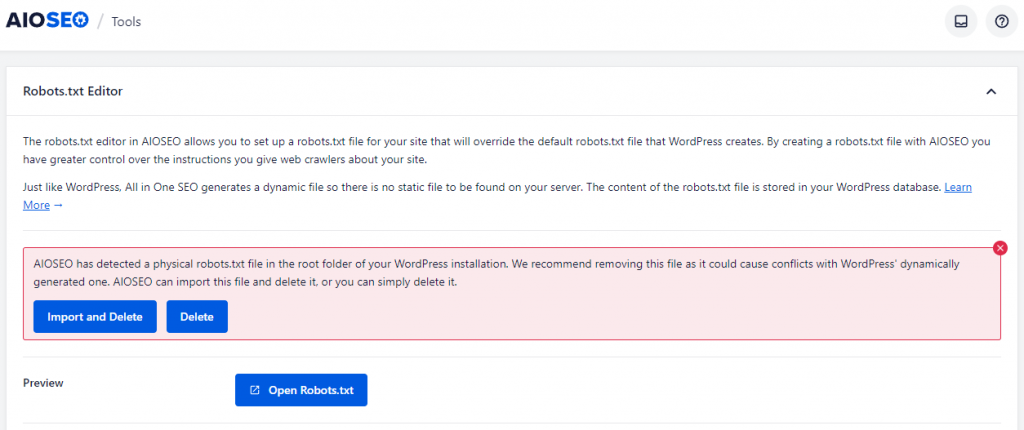
当我们网站根目录,已经存在robots.txt静态文件时,使用AIOSEO插件生成,会出现上面错误提示,因为这些插件是使用的虚拟的Robots文件(即不会在网站目录创建真实的静态文件),如果同时保留两者,出现Robots冲突。
5. 测试Robots文件
测试 Robots.txt 文件可以通过以下几种方式进行:
浏览器访问测试
在浏览器中访问 http://xxxx/robots.txt,确保文件能够正确显示。

Google Search Console工具测试
-
- 登录 Google Search Console。
- 选择查看的网站。
- 在左侧导航菜单中,找到“设置”部分,点击抓取部分的 “robots.txt”。
- 即可查看到robots.txt 文件的状态

第三方在线工具测试
可以使用一些在线工具来测试你的 robots.txt 文件,
例如:Technicalseo Robots.txt Tester

这些工具可以帮助我们检查 Robots.txt 文件是否正确,并确保搜索引擎爬虫能够正确解析和遵循其中的规则。
以上就是今天文章的全部内容了,希望能对你了解Robots.txt有帮助。另外,为了帮助大家更全面地掌握技术SEO的相关知识,我们也准备了一份详尽的谷歌SEO运营指南,点击即可免费领取高清版。另外我们也提供谷歌SEO服务,有这方面需求的朋友们可以随时联系我们~

以上内容由霆万科技/霆万出海学院原创/转载,请勿私自转载,以免侵权!如需转载,请扫码添加客服,获得授权并注明来源。